Forum
8.3 HYPOTHESEN, STATISTISCHE TESTS
![]()
EINFÜHRUNG |
Du machst eine Hypothese (genannt Nullhypothese), beispielsweise dass eine vor dir liegende Münze nicht gefälscht ist , d.h. dass die Wahrscheinlichkeit für Kopf und Zahl gleich gross sind (p = ½). Oder du hast einen Würfel vor dir und machst die Hypothese, dass dieser nicht gezinkt ist, d.h. dass alle 6 Zahlen mit der gleichen Wahrscheinlichkeit p = 1/6 auftreten. In diesem Kapitel lernst du ein Verfahren kennen, um deine Hypothese zu prüfen, allerdings auch hier wieder nicht mit absoluter Sicherheit, sondern du lässt zu, dass du dich beim Verwerfen der Hypothese mit der Wahrscheinlichkeit 5 % (Signifikanzniveau) täuschst. |
EINE SIGNIFIKANT GEFÄLSCHTE MÜNZE |
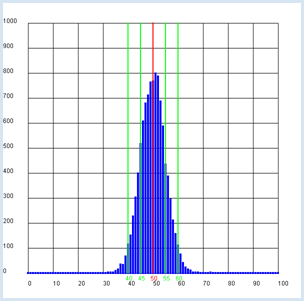
Gehst du von der Nullhypothese aus, dass die Münze nicht gefälscht ist und wirfst du ihn n = 100 Mal, so erhältst du eine bestimmte Anzahl k mal Kopf und n - k mal Zahl.
Du zeichnest auch noch den Bereich mit 95% aller Fälle ein und erhältst etwa die doppelte Streuung (hier zwischen 40 und 60). from gpanel import * from random import random n = 100 # size of the test group p = 0.5 z = 10000 def showDistribution(): setColor("blue") lineWidth(4) for t in range(n + 1): line(t, 0, t, h[t]) def showMean(): global mean count = 0 for t in range(n + 1): count += h[t] * t mean = int(count / z + 0.5) setColor("red") lineWidth(2) line(mean, 0, mean, 1000) text(mean - 1, -30, str(mean)) def showSpreading(level): count = h[mean] for s in range(1, 20): count += h[mean + s] + h[mean - s] if count > z * level: break setColor("green") lineWidth(2) line(mean + s, 0, mean + s, 1000) text(mean + s - 1, -30, str(mean + s)) line(mean - s, 0, mean - s, 1000) text(mean - s - 1, -30, str(mean - s)) def sim(): count = 0 repeat n: w = random() if w < p: count +=1 return count makeGPanel(-0.1 * n, 1.1 * n, -100, 1100) title("Coin toss, distribution of number") drawGrid(0, n, 0, 1000) h = [0] * (n + 1) repeat z: k = sim() h[k] += 1 showDistribution() showMean() showSpreading(0.68) showSpreading(0.95)
|
MEMO |
|
Machst du oft eine Stichprobe mit 100 Münzen, die nicht gefälscht sind, so liegen in 68 % aller Fälle die Zahl der geworfenen Köpfe im Bereich 50 +-5, in 95% aller Fälle im Bereich 50 +-10 [mehr...
Der theoretisch berechnete Wert ist Machst du also mit deiner vor dir liegenden Münze einen Hundertertest und erhältst für die Anzahl Köpfe einen Wert, der grösser als 60 oder kleiner als 40 ist, so verwirfst du die Hypothese, dass die Münze nicht gefälscht ist, d.h. du sagst, die Münze sei gefälscht. Dabei irrst du dich mit einer Wahrscheinlichkeit von 5 % (genannt Signifikanzniveau). Manchmal sagst du auch prägnant, die vorliegende Münze ist signifikant gefälscht. |
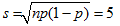
EIN SIGNIFIKANT GEZINKTER WÜRFEL |
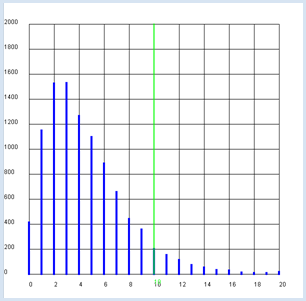
Du hast einen Würfel vor dir und möchtest testen, ob es sich um einen fairen Würfel handelt, bei dem alle Augenzahlen mit der Wahrscheinlichkeit 1/6 auftreten. Du machst daher die Hypothese: Der Würfel ist nicht gezinkt. Du lernst hier ein etwas anderes Verfahren als bei der Münze kennen, da bei einem Wurf nicht nur zwei, sondern 6 Möglichkeiten auftreten, nämlich die Augenzahlen 1 bis 6. Um auf sicher zu gehen, wirfst du den Würfel oftmals, sagen wir 600 mal und schreibst dir die Häufigkeiten der Augenzahlen auf.
Beobachtete und theoretische Häufigkeit
Um ein Mass für die Abweichung der Beobachtung von der Theorie einzuführen, berechnest du für jede Augenzahl die relative quadratische Abweichung (u - e)2 / e und summierst diese Werte auf. Das Resultat nennen wir χ2 (ausgesprochen "Chi-Quadrat").
from gpanel import * from random import random, randint n = 600 # number of tosses p = 1 / 6 z = 10000 def showDistribution(): setColor("blue") lineWidth(4) for i in range(21): line(i, 0, i, h[i]) def showLimit(level): count = 0 for i in range(21): count += h[i] if count > z * level: break setColor("green") lineWidth(2) line(i, 0, i, 2000) text(i, -80, str(i)) return i def chisquare(u): chi = 0 e = n * p for i in range(1, 7): chi += ((u[i] - e) * (u[i] - e)) / e return chi def sim(): u = [0] * 7 repeat n: t = randint(1, 6) u[t] += 1 return chisquare(u) makeGPanel(-2, 22, -200, 2200) title("Chi-square simulation is being carried out. Please wait...") drawGrid(0, 20, 0, 2000) h = [0] * 21 repeat z: c = int(sim()) if c < 20: h[c] += 1 else: h[20] += 1 title("Chi-square test on the die") showDistribution() s = showLimit(0.95) # Observed series u1 = [0, 112, 128, 97, 103, 88, 72] u2 = [0, 112, 108, 97, 113, 88, 82] c1 = chisquare(u1) c2 = chisquare(u2) print("Die with", u1, "Xi-square:", c1, "loaded?", c1 > s) print("Die with", u2, "Xi-square:", c2, "loaded?", c2 > s)
|
MEMO |
|
Die Computersimulation ergibt folgendes Resultat: In 95% aller Fälle ist χ2 kleiner oder gleich dem kritischen Wert 11. Damit hast du ein Verfahren gefunden um zu prüfen, ob dein Würfel gezinkt ist: Du berechnest aus der beobachteten Häufigkeit χ2. Ist der Wert grösser als 11, so kannst du mit 5% Irrtumswahrscheinlichkeit sagen, dass deine Nullhypothese eines fairen Würfels falsch ist, der Würfel also gezinkt ist. Mit den Häufigkeiten aus der oberen Tabelle ergibt sich χ2 = 18.7. Der Würfel ist also mit mit grosser Wahrscheinlichkeit gezinkt. Mit einem anderen Würfel erwürfelst du mit 600 Würfen die Häufigkeiten u2 = [112, 108, 97, 113, 88, 82]. Da du daraus χ2 = 8.5 berechnest, ist dieser Würfel mit grosser Wahrscheinlichkeit nicht gezinkt. |
UNTERSCHIEDE IM MENSCHLICHEN VERHALTEN |
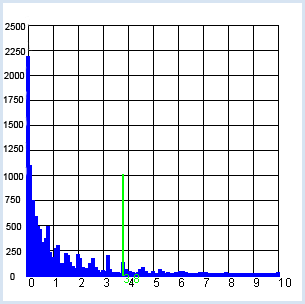
Den χ2-Test kannst du auch auf eine Untersuchung über das Verhalten von zwei Menschengruppen anwenden. Interessant ist oft die Frage, ob das Verhalten in einem bestimmten Kontext von weiblichen und männlichen Personen als statistisch unterschiedlich taxiert werden muss, oder ob sie sich beide Gruppen gleich verhalten. Du gehst davon aus, dass in einer Sekundarschule die Verwendung von Facebook untersucht wird. Dabei werden in Parallelklassen einer Sekundarschule insgesamt 106 Mädchen (Frauen) und 86 Knaben (Männer) gefragt, ob sie ein Facebook-Konto besitzen. Die Umfrage ergibt:
Der prozentuale Anteil ist zwar bei Frauen wesentlich grösser als bei Männern. Es stellt sich aber die Frage, ob dieser Mehranteil statistisch signifikant ist.
Für alle vier Fälle musst du nun noch der Erwartungswert e bestimmen. Gehst du davon aus, dass p = (f0 + m0) / n die Gesamtwahrscheinlichkeit für ein Ja und entsprechend 1 - p die Gesamtwahrscheinlichkeit für ein Nein ist, so berechnest du
Das übrige Programm bleibt gegenüber dem Würfeltest weitgehend unverändert. from gpanel import * from random import random z = 10000 # survey values/polls females_yes = 87 females_no = 19 males_yes = 62 males_no = 24 def showDistribution(): setColor("blue") lineWidth(4) for i in range(101): line(i/10, 0, i/10, h[i]) def showLimit(level): count = 0 for i in range(101): count += h[i] if count > level * z: break setColor("green") lineWidth(2) limit = i / 10 line(limit, 0, limit, 1000) text(limit, -80, str(limit)) return limit def chisquare(f0, f1, m0, m1): # f: females, m: males, 0:yes, 1:no w = (f0 + m0) / n # probability of a yes # expected value ef0 = (f0 + f1) * w # females-yes em0 = (m0 + m1) * w # males-yes ef1 = (f0 + f1) * (1 - w) # females-no em1 = (m0 + m1) * (1 - w) # males-no # add up deviations (u - e)*(u - e) / e chi = (f0 - ef0) * (f0 - ef0) / ef0 \ + (m0 - em0) * (m0 - em0) / em0 \ + (f1 - ef1) * (f1 - ef1) / ef1 \ + (m1 - em1) * (m1 - em1) / em1 return chi def sim(): # simulate females f0 = 0 # yes f1 = 0 # no for i in range(females_all): t = random() if t < p: f0 += 1 else: f1 += 1 # simulate males m0 = 0 # yes m1 = 1 # no for i in range(males_all): t = random() if t < p: m0 += 1 else: m1 += 1 return chisquare(f0, f1, m0, m1) females_all = females_yes + females_no males_all = males_yes + males_no n = females_all + males_all # all p = (females_yes + males_yes) / n # probability of yes for all print("Facebook yes (all):", round(100 * p, 1), "%") pf = females_yes / females_all print("Facebook yes (females):", round(100 * pf, 1), "%") pm = males_yes / males_all print("Facebook yes (males:)", round(100 * pm, 1), "%") makeGPanel(-1, 11, -250, 2750) title("Chi-square test, use of Facebook") drawGrid(0, 10, 0, 2500) h = [0] * 101 repeat z: c = int(10 * sim()) # magnification factor of 10 if c < 100: h[c] += 1 else: h[100] += 1 showDistribution() s = showLimit(0.95) c = chisquare(females_yes, females_no, males_yes, males_no) print("critical value:", s) print("observed:", c) if c <= s: print("- the same behavior") else: print("- not the same behavior")
|
MEMO |
|
Das Resultat ist erstaunlich: Die χ2-Signifikanzgrenze liegt bei 3.8 [mehr... Der Wert entspricht dem Wert aus der χ2-Tabelle für 1 Freiheitsgrad einer Signifikanz von 0.95]. Für die Umfragewerte ergibt sich der kleinere Wert 2.7. Trotzdem bei den Mädchen der Kontenanteil wesentlich höher ist, kann also statistisch nicht bewiesen werden, dass sie sich bezüglich Facebook wesentlich von den Knaben unterscheiden. |
AUFGABEN |
|