![]()
INTRODUCTION |
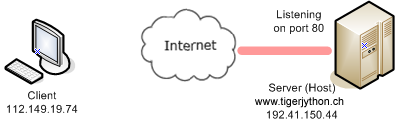
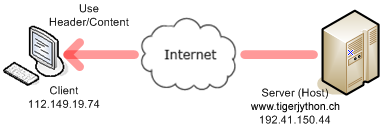
Vous savez déjà qu’une page Web affichée dans le navigateur Web est décrite par un fichier texte ordinaire au format HTML qui est typiquement situé sur une machine distante, également appelée hôte. Pour être en mesure de localiser le fichier, le navigateur utilise une URL de la forme http://hostname/filepath structurée de la manière suivante:
L’échange de données comporte plusieurs phases distinctes détaillées dans les schémas ci-dessous:
|
REQUÊTE HTTP POUR OBTENIR UNE PAGE WEB |
|
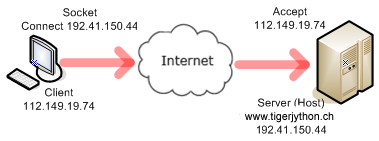
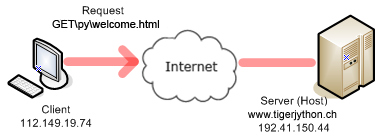
Le programme suivant effectue les phases 1, 2 et 4 pour obtenir le fichier welcome.html situé dans le sous-dossier py à la racine du serveur Web. La méthode socket() de la classe socket stocke dans la variable s un objet socket. Cette méthode prend deux paramètres qui sont des constantes et qui indiquent le type de socket à créer. import socket host = "www.tigerjython.ch" port = 80 # Phase 1 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) # Phase 2 request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) # Phase 4 reply = s.recv(4096) print("\nReply:\n") print(reply) |
MEMENTO |
|
Lorsqu’un navigateur Web (client HTTP) demande une page Web, il le fait en utilisant le protocole HTTP. Il s’agit d’une série de conventions, suivies par le client et le serveur, déterminant de manière très précise les procédures à utiliser pour l’échange de données. La commande (on parle de méthode dans le jargon du HTTP) GET est définie de la manière suivante dans la spécification du protocole [plus.. Les protocoles liés à lInternet sont discutés et décrits sous la forme de documents appelés RFC (Request For Comments). Le protocole HTTP est défini par la RFC 2616]:
|
UTILISATION DE HTTPS |
Au lieu de HTTP, de plus en plus de sites Web nécessitent le protocole HTTPS, où les données sont cryptées à l'aide de SSL (Secure Socket Layer). Pour un tel serveur, une requête HTTP sur le port 80 pourrait produire un message d'erreur, comme dans le programme suivant pour le serveur github.com: import socket host = "www.github.com" port = 80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) print("\nReply:\n") print(reply) La réponse est: HTTP/1.1 301 Moved Permanently Content-length: 0 Location: https://www.github.com/py/welcome.html Mais il est très facile de modifier la requête en HTTPS. Pour cela, changez le port sur 443 et insérez une ligne avec ssl.wrap_socket (). import socket import ssl host = "github.com" port = 443 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) s = ssl.wrap_socket(s) request = "GET / HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) print("\nReply:\n") print(reply) |
EN-TÊTES HTTP ET CONNECT |
|
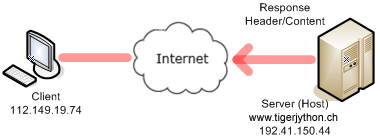
La réponse du serveur est constituée d’en-têtes servant à préciser des informations d’état ainsi que le contenu à proprement parler qui est le document HTML. Avant de pouvoir effectuer le rendu du code HTML reçu, il faut donc supprimer les informations d’en-têtes pour ne conserver que le code HTML et le transmettre à un HtmlPane. import socket from ch.aplu.util import HtmlPane host = "www.tigerjython.ch" port = 80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host , port)) request = "GET /py/welcome.html HTTP/1.1\r\nHost: " + host + "\r\n\r\n" s.sendall(request) reply = s.recv(4096) index = reply.find("<html") html = reply[index:] pane = HtmlPane() pane.insertText(html) |
MEMENTO |
|
La fonction recv(4096) rend un maximum de 4096 caractères d'une mémoire de données dans laquelle les caractères reçus sont copiés. Pour supprimer les en-têtes de la réponse, on peut utiliser la méthode find(str) de la classe str permettant de rechercher la sous-chaine sub_str dans la chaîne str en retournant l’indice de la première occurrence. Si la sous-chaîne sub_str n’est pas trouvée dans str, la fonction retourne -1. Une fois que l’on connaît l’indice de la première occurrence de la sous-chaîne, on peut facilement supprimer tout ce qui la précède grâce à l’opérateur de slicing, str[start :] qui ne conserve que la partie de la chaine à partir de l’indice start jusqu’à la fin. |
LECTURE DES PRÉVISIONS MÉTÉOROLOGIQUES |
|
Vous vous demandez peut-être s’il est vraiment utile d’implémenter une procédure aussi compliquée pour afficher une page Web alors qu’il serait possible de n’écrire qu’une seule ligne ayant recours à la méthode insertUrl() du HtmlPane. Ce que vous avez appris par-là sera très utile si, au lieu de vouloir simplement afficher ce code HTML dans un HtmlPane, vous voulez en extraire une information bien précise. Le programme ci-dessous sert par exemple à lire le code HTML du site du bureau australien de météorologie pour en extraire les prévisions météorologiques actuelles. Vous pouvez vous simplifier la vie encore davantage en utilisant la bibliothèque urllib2 au lieu de créer explicitement le socket permettant de télécharger le code HTML du site [plus... Une bibliothèque (on parle de module ou de package dans le jargon Python) ajoute une couche dabstraction permettant de présenter à lapplication des fonctions simples à invoquer alors quelles exécutent en fait un code compliqué à mettre en uvre. Les informaticiens parlent dune couche dabstraction « haut niveau » au-dessus du code « bas niveau » sous-jacent].Pour situer l’information désirée dans le code HTML, le programme d’analyse suivant représente le code HTML reçu à la fois dans la console de Python et dans le navigateur par défaut. import urllib2 from ch.aplu.util import HtmlPane url = "http://www.weatherzone.com.au" HtmlPane.browse(url) html = urllib2.urlopen(url).read() print html |
MEMENTO |
|
L’utilisation d’une bibliothèque logicielle telle qu’urllib2 simplifie grandement le code mais présente le désavantage d’occulter les mécanismes de base nécessaires à l’implémentation de la fonctionnalité. |
ANALYSE SYNTAXIQUE DE TEXTES |
|
Vous êtes maintenant confrontés à la tâche fort intéressante et non triviale consistant à extraire l’information pertinente d’une longue de chaîne de caractères : c’est ce qu’on appelle l’analyse syntaxique du texte. Dans un premier temps, il faut supprimer toutes les balises HTML à l’aide d’une fonction remove_html_tags(). Il s’agit d’une procédure bien typique dont l’algorithme peut être décrit de la manière suivante: On parcourt le texte caractère à caractère en mémorisant deux états distincts : ou bien le caractère lu se trouve à l’intérieur d’une balise HTML ou il se trouve à l’extérieur. Il faut uniquement copier les caractères de la chaine analysée si l’on ne se trouve pas à l’intérieur d’une balise ouvrante ou fermante. Les changements d’état se produisent lorsque l’on est en train de lire les caractères < ou > marquant le début ou la fin d’une balise. Avant d’être en mesure de développer une fonctionnalité permettant d’extraire l’information voulue, il faut analyser le contenu du texte après épuration des balises HTML. Cela consiste essentiellement à copier le texte dépourvu des balises HTML dans un éditeur de texte et à chercher une séquence de caractères marquant de manière unique le début de l’information recherchée ainsi qu’une séquence de caractères marquant la fin de cette information. La méthode str.find() sera alors d’un grand secours pour trouver l’indice start marquant le début de l’information. Pour trouver l’indice end marquant la fin de l’information, on réutilise str.find() en recherchant à partir de start. Pour ce site Web, la séquence de caractères du début est « State Weather » et la séquence de fin est « National Summary ». Le texte se trouvant entre les deux est extrait par une opération de slicing [start:end]. import urllib2 def remove_html_tags(s): inTag = False out = "" for c in s: if c == '<': inTag = True elif c == '>': inTag = False elif not inTag: out = out + c return out url = "http://www.weatherzone.com.au" html = urllib2.urlopen(url).read() html = remove_html_tags(html) start = html.find("National Summary") end = html.find("State Weather", start) html = html[start:end].strip() print html |
MEMENTO |
|
The parsing of texts is usually done character by character. In many cases, however, methods of the string class may help as well [plus...les programmeurs expérimentés utilisent souvent la théorie des expressions régulières pour effectuer lanalyse syntaxique dun texte]. En HTML, les caractères spéciaux et accentués sont encodés de manière spéciale à laide de séquences appelées entités HTML débutant par une esperluette & et se terminant par un point-virgule ; selon la table suivante:
|
SYNTHÈSE VOCALE / LECTURE DE LA MÉTÉO |
|
En utilisant les connaissances acquises dans un précèdent chapitre portant sur le son, vous êtes en mesure de créer un programme qui va utiliser la synthèse vocale pour lire automatiquement les prévisions météorologiques en quelques lignes de code: from soundsystem import * initTTS() selectVoice("german-man") sound = generateVoice(html) openSoundPlayer(sound) play() |
EXERCICES |
|