Forum
9.1 PERSISTENZ, DATEIEN
![]()
EINFÜHRUNG |
In der heutigen High-Tech-Gesellschaft spielen computergespeicherte Informationen, kurz Daten genannt, eine zentrale Rolle. Obschon sie mit geschriebenem Text vergleichbar sind, gibt es mehrere wichtige Unterschiede:
Persistente Daten werden mit Computerprogrammen auf einen physikalischen Datenträger (typisch: Festplatte (HD), Solid State Disk (SSD), Speicherkarte (Memory Stick)) als Dateien geschrieben bzw. gelesen. Dabei handelt es sich um Speicherbereiche mit einer bestimmten Struktur und einem bestimmten Dateiformat. Da die Datenübertragung auch über grosse Distanzen schnell und billig geworden ist, werden Dateien immer häufiger auch auf weit entfernten Datenträgern (Clouds) abgelegt. Dateien werden auf dem Computer in einer hierarchischen Verzeichnisstruktur verwaltet, d.h. in einem bestimmten Verzeichnis können sich Dateien, aber auch Unterverzeichnisse befinden. Der Zugriff erfolgt über den Dateipfad (kurz Pfad), der die Verzeichnisse und den Dateinamen enthält. Das Dateisystem ist aber betriebssystemabhängig, sodass es gewisse Unterschiede zwischen Windows, Mac und Linux-Systemen gibt. |
TEXTDATEIEN LESEN UND SCHREIBEN |
Du hast bereits im Kapitel Internet gelernt, wie man in Python Textdateien lesen kann. In Textdateien sind die Zeichen zwar hintereinander (sequentiell) abgelegt, aber man erhält eine Zeilenstrukturierung wie auf einem Blatt Papier durch Einfügen von Zeilenendzeichen. Gerade hier unterscheiden sich die Betriebssysteme: Während bei Mac und Linux als Zeilenendzeichen (End of Line, EOL) das ASCII-Zeichen <line feed> verwendet wird, ist es bei Windows die Kombination von <carriage return><line feed>. In Python werden diese Zeichen mit \r bzw. \n codiert [mehr...
Liest man unter Windows eine Textdatei oder eine Zeile in einen String ein, In deinem Programm verwendest du deutschsprachige Wortlisten, die als Textdateien vorliegen. Du kannst sie als tfwordlist.zip von hier downloaden und in irgend einem Verzeichnis auspacken. Kopiere die Dateien worte-1$.txt und verben-1$.txt in das Verzeichnisses, in dem sich dein Programm befindet. Du stellst dir hier die interessante Frage, welche Wörter Palindrome sind. Darunter versteht man Wörter, die von vorne und hinten gelesen gleich lauten, wobei die Gross-Kleinschreibung nicht berücksichtigt wird. Mit open() erhältst du ein Fileobjekt f zurück, das dir den Zugang zur Datei vermittelt. Du kannst nachher mit einer einfachen for-Schleife alle Zeilen durchlaufen. Dabei musst du beachten, dass die einzelnen Zeilen ein Zeilenendzeichen enthalten, das du zuerst mit einer Slice-Operation wegschneiden musst, bevor du das Wort von hinten liest. Zudem solltest du noch alle Zeichen mit lower() auf Kleinschreibung konvertieren. Das Umkehren eines Strings ist in Python etwas trickreich. Die Slice-Operation lässt nämlich auch negative Indizes zu, wobei in diesem Fall die Indizes-Zählung am Ende des Strings beginnt. Wählst du als step-Parameter -1, so wird der String von hinten her durchlaufen. def isPalindrom(a): return a == a[::-1] f = open("worte-1$.txt") print("Searching for palindroms...") for word in f: word = word[:-1] # remove trailing \n word = word.lower() # make lowercase if isPalindrom(word): print(word) f.close() print("All done")
Du kannst auch mit der Methode readline() Zeile um Zeile lesen. Dabei wird bei jedem Aufruf sozusagen ein Zeilenzeiger vorgeschoben. Wenn du am Ende der Datei angekommen bist, liefert die Methode einen leeren String zurück. Du speicherst das Resultat in einer Datei mit dem Namen palindrom.txt. Um in die Datei zu schreiben, musst du diese zuerst mit open() und dem Parameter "w" (für write) erstellen und mit der Methode write() hineinschreiben. Am Schluss darfst du close() nicht vergessen, damit sicher alle Zeichen in die Datei geschrieben und die Betriebssystem-Ressourcen wieder frei gegeben werden. def isPalindrom(a): return a == a[::-1] fInp = open("worte-1$.txt") fOut = open("palindrom.txt", "w") print("Searching for palindroms...") while True: word = fInp.readline() if word == "": break word = word[:-1] # remove trailing \n word = word.lower() # make lowercase if isPalindrom(word): print(word) fOut.write(word + "\n") fInp.close() fOut.close() print("All done")
|
MEMO |
|
Beim Öffnen von Textdateien mit open(path, mode) wird mit dem Parameter mode der Benützungsmodus angegeben.
Wenn du alle Zeilen einer Datei gelesen hast und sie nochmals lesen willst, so musst du entweder die Datei schliessen und wieder öffnen, oder einfacher die Methode seek(0) des Fileobjekts aufrufen. Du kannst auch den gesamten Inhalt der Textdatei mit text = f.read() in einen String einlesen und dann die Datei schliessen. Mit textList = text.splitlines() erstellst du eine Liste mit den Zeilenstrings (ohne Zeilenendzeichen). Weitere wichtige Dateioperationen:
|
OPTIONEN/SPIELDATEN SPEICHERN UND WIEDERHERSTELLEN |
Dateien werden oft dazu verwendet, einen Zustand zu speichern (man sagt auch, zu retten), damit er bei der nächsten Ausführung des Programms wieder hergestellt werden kann. Dies betrifft beispielsweise Programmeinstellungen (Optionen), die der Benutzer vorgenommen hat, um das Programm seinen Wünschen anzupassen. Vielleicht möchtest du aber auch den gegenwärtigen Spielzustand eines Spiels speichern, damit du später genau in dieser Situation weiter spielen kannst. Optionen und Zustände lassen sich meist elegant als Schlüssel-Werte-Paare speichern, wobei der Schlüssel (key) ein Bezeichner für den Wert (value) ist. Beispielsweise gibt es für die TigerJython IDE bestimmte Konfigurationswerte (Setup-Parameter):
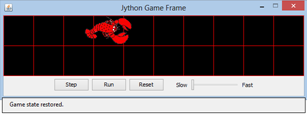
Wie du im Kapitel 6.3 gelernt hast, kann man solche Key-Value-Paare in einem Python Dictionary speichern, das du mit dem Modul pickle sehr einfach als (binäre) Datei abspeichern und wiederherstellen kannst. Im folgenden Beispiel speicherst du beim Schliessen des Gamefensters die aktuelle Position und Richtung des Hummers und die Stellung des Simulationszyklus-Reglers. Beim nächsten Starten werden die abgespeicherten Werte wieder hergestellt.
import pickle import os from gamegrid import * class Lobster(Actor): def __init__(self): Actor.__init__(self, True, "sprites/lobster.gif"); def act(self): self.move() if not self.isMoveValid(): self.turn(90) self.move() self.turn(90) makeGameGrid(10, 2, 60, Color.red) addStatusBar(30) show() path = "lobstergame.dat" simulationPeriod = 500 startLocation = Location(0, 0) if os.path.isfile(path): inp = open(path, "rb") dataDict = pickle.load(inp) inp.close() # Reading old game state simulationPeriod = dataDict["SimulationPeriod"] loc = dataDict["EndLocation"] location = Location(loc[0], loc[1]) direction = dataDict["EndDirection"] setStatusText("Game state restored.") else: location = startLocation direction = 0 clark = Lobster() addActor(clark, startLocation) clark.setLocation(location) clark.setDirection(direction) setSimulationPeriod(simulationPeriod) while not isDisposed(): delay(100) gameData = {"SimulationPeriod": getSimulationPeriod(), "EndLocation": [clark.getX(), clark.getY()], "EndDirection": clark.getDirection()} out = open(path, "wb") pickle.dump(gameData, out) out.close() print("Game state saved")
|
MEMO |
|
Mit den Methoden pickle.dump() wird ein Dictionary in einer Datei gespeichert. Es handelt sich um eine binäre Datei, die du nicht direkt editieren kannst. |
AUFGABEN |
|
ZUSATZSTOFF |
WORTLISTEN SELBST ERSTELLEN |
Wortlisten sind begehrt, da sie in vielen Zusammenhängen verwendet werden, beispielsweise in Korrekturprogrammen, Passwortgeneratoren, Wortspielen (z.B. Scrabble), usw. Wortlisten sind als Textdateien kommerziell erhältlich, aber teuer. Du kannst dir Wortlisten gratis selbst zusammenstellen, indem du die Wörter aus bestehenden Korrekturhilfedateien (Wörterbücher & Sprachpakete) von Gratisprogrammen herausfilterst, beispielsweise aus einem Mailprogramm (Thunderbird). Für eine Wortliste in Deutsch gehst du auf die Website https://www.j3e.de/ispell/igerman98 und lädst eine Datei mit dem Namen igerman98-xxx.tar.gz herunter (xxx kann irgend etwas sein). Nachdem du sie ausgepackt hast, findest du einige Wortlisten als Textdateien. Kopiere diese in ein Verzeichnis und öffne sie mit einem Texteditor. Wie du siehst, sind die Wörter zwar enthalten, müssen aber noch etwas aufgearbeitet werden. Dazu eignet sich ein kleines Pythonprogramm hervorragend. Für die Konvertierung der Wortlisten aus igerman98 ist folgende Konvertierung angebracht:
def toUmlaut(c): if c == "A": return "Ä" if c == "O": return "Ö" if c == "U": return "Ü" if c == "a": return "ä" if c == "o": return "ö" if c == "u": return "ü" def convert(infile, outfile): inFile = open(infile, "r") outFile = open(outfile, "w") for line in inFile: # Cut at trailing / index = line.find("/") if index != -1: # found line = line[0:index + 1] # Insert umlaute line1 = "" i = 0 while i < len(line) - 1: # don't include trailing \n pair = line[i : i + 2] if pair[1] == "\"": # indicates Umlaut line1 = line1 + toUmlaut(pair[0]) i += 1 elif pair == "sS": # indicates sz line1 = line1 + "ss" i += 1 elif pair == "qq": i += 2 # skip "qq" else: line1 = line1 + pair[0] i += 1 outFile.write(line1 + "\n") inFile.close() outFile.close() convert("verben.txt", "verben-1$.txt") print("All done")
|
MEMO |
|
Die von Thunderbird heruntergeladenen Wörterbücher besitzen die Dateierweiterung .xpi. Du kannst sie durch .zip ersetzen und die Datei wie ein ZIP-Archiv öffnen. |